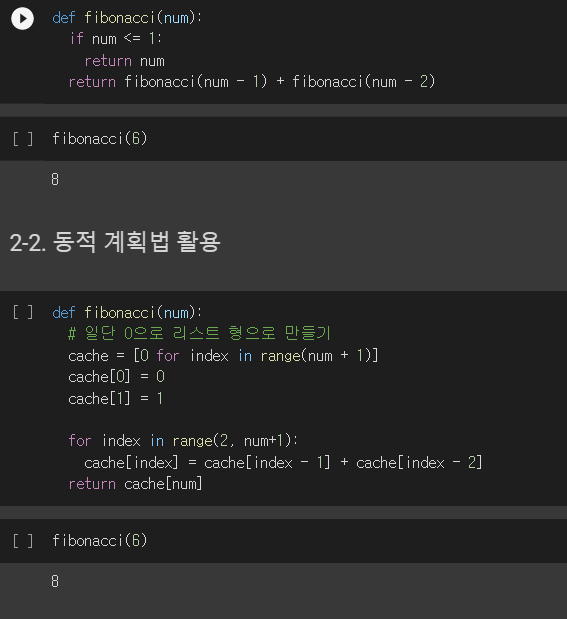
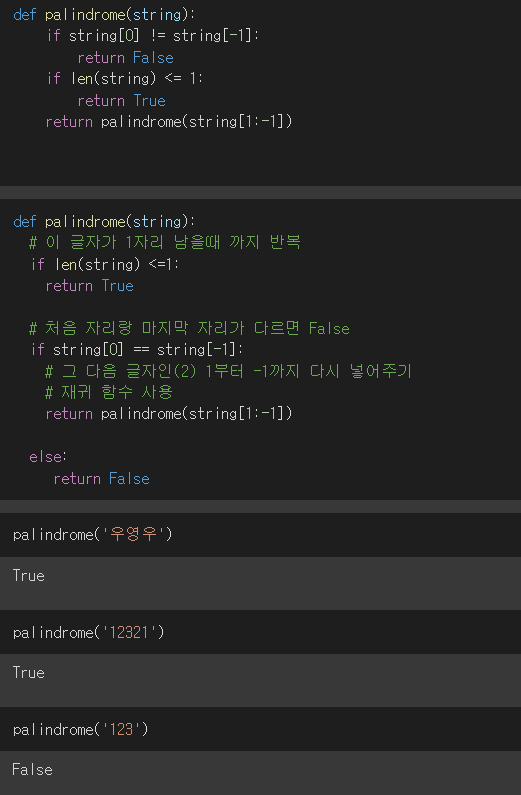
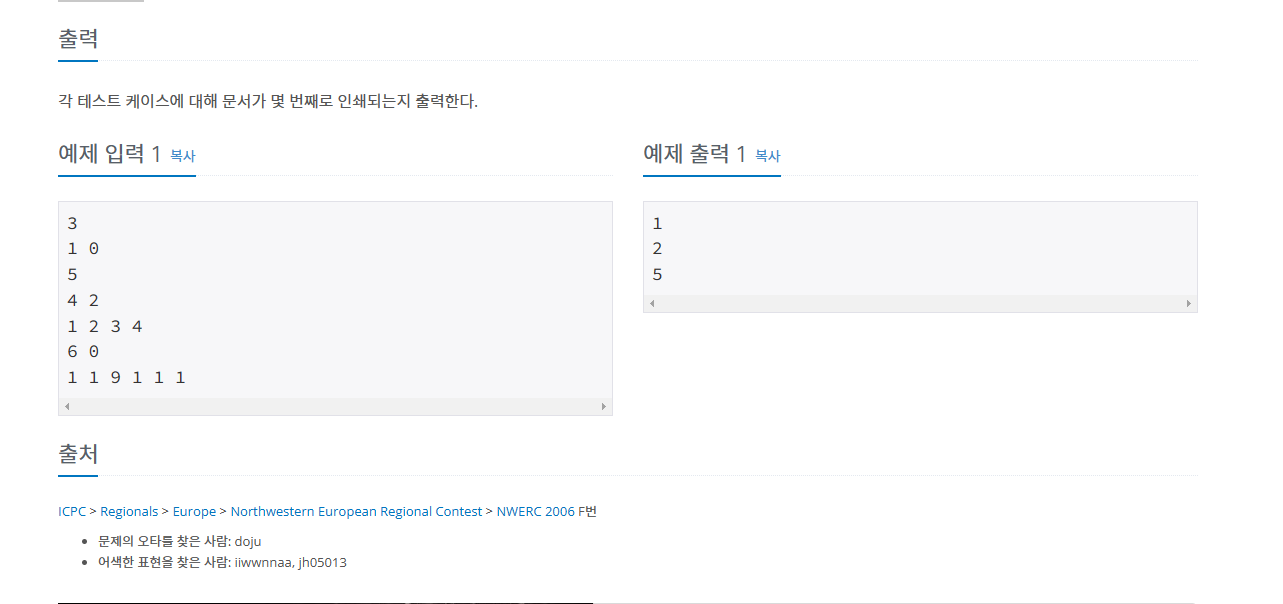
1. 동적 계획법(Dynamic Programming) 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분의 값을 활용해서 보다 큰 크기의 부분 문제를 해결함 상향식 접근법(최하위 해답을 구한 후 해당 결과를 이용해서 상위 문제를 풀어가는 방식) 프로그램 실행 시 이전의 계산한 값을 저장하여 다시 계산하지 않도록 전체 실행 속도를 빠르게 하는 기술(메모이제이션 : Memoization)을 사용 문제를 잘게 쪼갤 때, 부분 문제는 중복되기 때문에 재활용 2. 동적 계획법 알고리즘 피보나치 수열 n을 입력받아서 아래와 같이 계산 피보나치 수열 함수흫 '피보나치' fibonacci(0) : 0 fibonacci(1) : 1 fibonacci(2) : 1 fibonacci(3) : 2 fibonacci(4)..