728x90
반응형
1. 해쉬 테이블(Hash Table)
- 키(key)에 데이터(value)를 저장하는 데이터 구조
- 파이썬에서는 딕셔너리(dick)타입이 해쉬 테이블의 예
- key를 통해 데이터를 바로 찾을 수 있으므로 검색 속도가 빠름
- 보통 배열로 미리 Hash Table 사이즈 만큼 생성 후에 사용
2. 알아둘 용어
- 해쉬(Hash) : 임의의 값을 고정 길이로 변환하는 것
- 해쉬 테이블(Hash Table): 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해쉬 함수(Hashing Function) : key에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
- 해쉬 값(Hash Values) 또는 해쉬 주소(Hash Address) : key를 해싱 하무로 연산해서 해쉬 값을 알아내고 이를 기반으로 해쉬 테이블에 해당 key에 대한 데이터 위치를 일관성 있게 찾음
- 슬롯(Slot) : 한 개의 데이터를 저장할 수 있는 공간
3. 간단한 해쉬 예
3-1. 슬롯 만들기
[ ]
hash_table = list([0 for i in range(10)])# 10개의 칸으로 만들고 프린트
print(hash_table)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
3-2. 해쉬 함수 만들기
- 해쉬 함수는 다양하게 생성할 수 있으며 가장 간단한 방법으로 division법 (나누기를 통한 나머지 값을 사용하는 기법)을 사용해봄
[ ]
def hash_func(key):
return key % 10
3-3. 해쉬 테이블에 저장하기
- 데이터에 따라 필요시 key 생성 방법 정의가 필요함
[ ]
data1 = 'apple'
data2 = 'banana'
data3 = 'orange'
data4 = 'melon'
[ ]
# ord() : 문자의 아스키코드를 반환
print(ord(data1[0]))
print(ord(data2[0]))
print(ord(data3[0]))
print(ord(data4[0]))
97
98
111
109
[ ]
print(hash_func(ord(data1[0])))
print(hash_func(ord(data2[0])))
print(hash_func(ord(data3[0])))
print(hash_func(ord(data4[0])))
7
8
1
9
[ ]
def storage_data(data, value):
key = ord(data[0])
hash_address = hash_func(key)
hash_table[hash_address] = value
[ ]
storage_data('apple','010-1111-1111')
[ ]
hash_table
[0, 0, 0, 0, 0, 0, 0, '010-1111-1111', 0, 0][ ]
storage_data('banana','010-2222-2222')
storage_data('orange','010-3333-3333')
storage_data('melon','010-4444-4444')
[ ]
hash_table
[0,
'010-3333-3333',
0,
0,
0,
0,
0,
'010-1111-1111',
'010-2222-2222',
'010-4444-4444']3-4. 해쉬 함수를 사용해서 해쉬함수를 수정하기
[ ]
hash('apple')
-3756472184613635755[ ]
hash('apple')
-3756472184613635755[ ]
hash('banana')
754177351106668074[ ]
def get_key(data):
return hash(data)
def hash_function(key):
return key % 10
def save_data(data, value):
hash_address = hash_function(get_key(data))
hash_table[hash_address] = value
def read_data(data):
hash_address = hash_function(get_key(data))
return hash_table[hash_address]
[ ]
hash_table = list([0 for i in range(10)])# 10개의 칸으로 만들고 프린트
print(hash_table)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[ ]
save_data('apple', '010-1111-1111')
[ ]
hash_table
[0, 0, 0, 0, 0, '010-1111-1111', 0, 0, 0, 0][ ]
read_data('apple')
4. 해쉬 테이블의 장단점
- 장점 *데이터 저장 및 읽기 속도가 빠름(검색 속도가 빠름)
- 해쉬는 키에 대한 데이터가 있는지 확인 쉬움
- 단점
- 저장공간이 많이 필요함
- 여러키에 해당하는 주소가 동일한 경우 충돌을 해결하기 위한 별도의 자료구조가 필요함
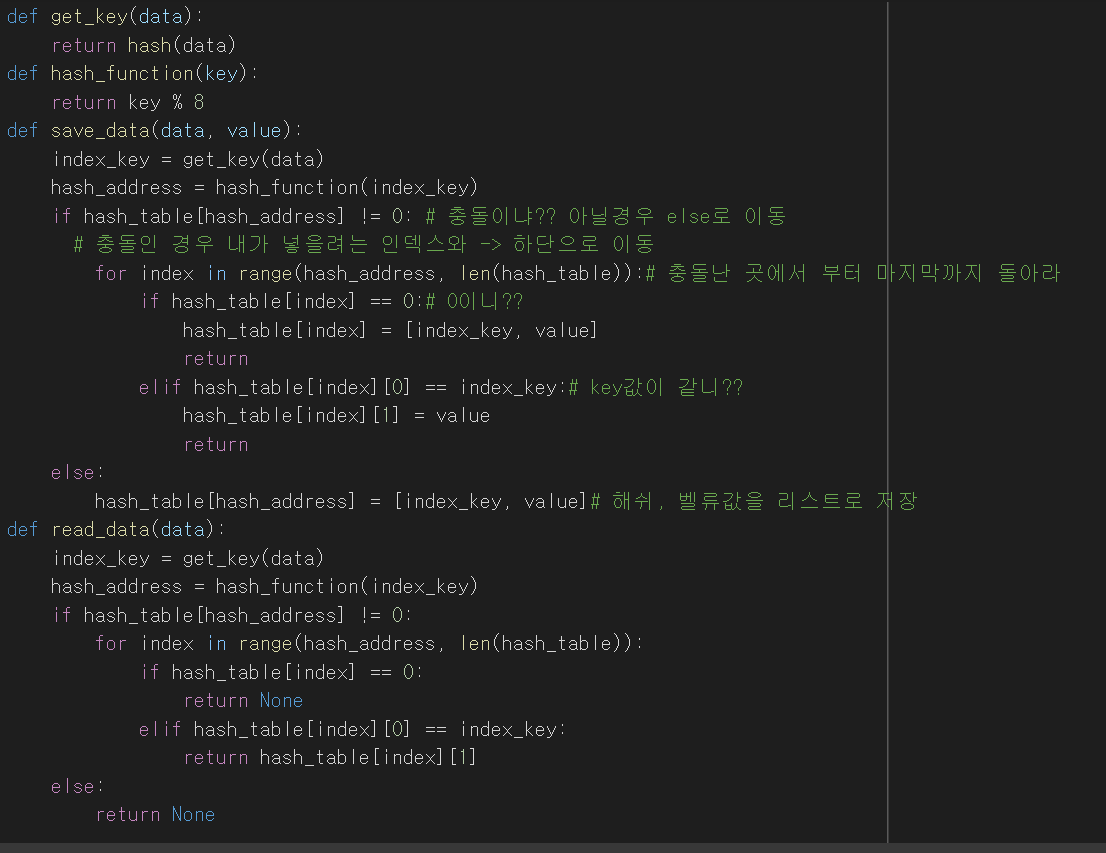
5. 충돌(Collision) 해결 알고리즘
5-1. Linear Probling 기법
- 패쇄 해싱 또는 clos Hashing 기법 중 하나
- 해쉬 테이블 저장공간 안에서 충돌 문제를 해결하는 기법
- 충돌이 일어나면 해당 hash address의 다음 address 부터 맨 처음 나오는 빈공간에 저장하는 기법
- 저장공간 활용도를 높이기 위한 방법
hash_table = list([0 for i in range(10)])# 10개의 칸으로 만들고 프린트
print(hash_table)
def get_key(data):
return hash(data)
def hash_function(key):
return key % 8
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0: # 충돌이냐?? 아닐경우 else로 이동
# 충돌인 경우 내가 넣을려는 인덱스와 -> 하단으로 이동
for index in range(hash_address, len(hash_table)):# 충돌난 곳에서 부터 마지막까지 돌아라
if hash_table[index] == 0:# 0이니??
hash_table[index] = [index_key, value]
return
elif hash_table[index][0] == index_key:# key값이 같니??
hash_table[index][1] = value
return
else:
hash_table[hash_address] = [index_key, value]# 해쉬, 벨류값을 리스트로 저장
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(hash_address, len(hash_table)):
if hash_table[index] == 0:
return None
elif hash_table[index][0] == index_key:
return hash_table[index][1]
else:
return None
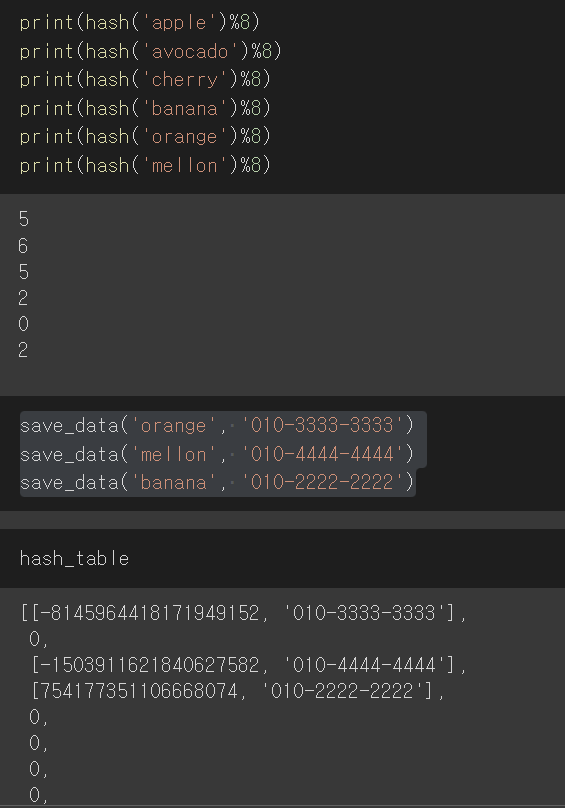
print(hash('apple')%8)
print(hash('avocado')%8)
print(hash('cherry')%8)
print(hash('banana')%8)
print(hash('orange')%8)
print(hash('mellon')%8)
save_data('orange', '010-3333-3333')
save_data('mellon', '010-4444-4444')
save_data('banana', '010-2222-2222')
hash_table
read_data('orange')
read_data('melon')
save_data('melon', '010-4444-4444')
hash_table5-2. Chaining 기법
- 개방 해쉬 또는 Open hashing 기법중 하나
- 해쉬 테이블 저장공간 외의 공간을 활용하는 방법
- 충돌이 일어나면 링크드 리스트 자료구조를 사용해서 링크드 리스트로 데이터를 추가로 뒤에 연결시켜 저장하는 방법
6. 해쉬 함수와 키 생성 함수
- SHA(Secure Hash Algorithm, 안전한 해쉬 알고리즘) 와 같은 유명한 해쉬 알고리즘을 많이 사용
- 어떤 데이터도 유일한 고정된 크기의 고정값을 리턴해주므로 해쉬 함수로 유용하게 활용할 수 있음
6-1. SHA-1
- 임의의 길이의 입력데이터 최대 160 비트(16진수 40자리)의 출력데이터(해시값)로 바꿈
- 파이썬의 hash() 함수는 환경에 따라 값이 매번 달라질 수 있음
import hashlib
data = 'test'.encode() # test 문자열을 바이트 단위로 바꿈
print(data)
hash_object = hashlib.sha1()
print(hash_object)
hash_object.update(data) # sh-1 객체로 data를 읽어옴
hex_dig = hash_object.hexdigest() # 16진수로 고정된 해쉬 값을 발생
print(hex_dig)
print(int(hex_dig, 16)) # 16진수로 고정된 해쉬값을 10진수의 고정된 해쉬값으로 반환
### 6-2. SHA-256
* SHA 알고리즘의 한 종류로 256비트로 구성되어 64자리 문자열을 반환
* SHA-2 계열 중 하나이며 블록체인에서 가장 많이 체택하여 사용
import hashlib # hash라이브러리
data = 'test'.encode()
print(data)
hash_object = hashlib.sha256()
print(hash_object)
hash_object.update(data)
hex_dig = hash_object.hexdigest()
print(hex_dig)
print(int(hex_dig, 16))### 문제
chaining 기법을 적용한 해쉬 테이블 코드에 키 생성함수 sha2 해쉬 알고리즘을 사용하도록 변경해보자
1. 해쉬 함수 : key%10
2. 해쉬 키 생성 : sha256(data)
import hashlib # hash라이브러리
hash_table = list([0 for i in range(10)])
def get_key(data):
hash_object = hashlib.sha256()
hash_object.update(data.encode())
hex_dig = hash_object.hexdigest()
return int(hex_dig, 16)
def save_data(data, value):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] !=0: # 해쉬 충돌 경우
for index in range(len(hash_table[hash_address])):
# 키가 동일한 경우 덮어쓰기
if hash_table[hash_address][index][0] == index_key:
hash_table[hash_address][index][1] = value
return
# 키가 동일하지 않으면 데이터 연결 저장
hash_table[hash_address].append([index_key, value])
# 해쉬 충돌 발생하지 않으면 그 공간에 데이터를 저장
else:
hash_table[hash_address] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] ==index_key:
return hash_table[hash_address][index][1]
return None
else:
return None
save_data('orange', '010-3333-3333')
save_data('mellon', '010-4444-4444')
save_data('banana', '010-2222-2222')
save_data('apple', '010-44433-3333')
save_data('cherry', '010-4664-4444')
save_data('avocado', '010-7777-7777')
hash_table
print(hash('apple')%10)
print(hash('avocado')%10)
print(hash('cherry')%10)
print(hash('banana')%10)
print(hash('orange')%10)
print(hash('mellon')%100)
read_data('avocado')반응형
'Python > 알고리즘&자료구조' 카테고리의 다른 글
| Python 자료구조&알고리즘 - 힙(Heap) (0) | 2023.02.01 |
|---|---|
| Python 자료구조&알고리즘 - 트리(Tree), 이진 탐색 (0) | 2023.01.31 |
| Python 알고리즘&자료구조 더블 링크드 리스트(Doubly Linked List) (0) | 2023.01.29 |
| Python 자료구조&알고리즘 - 링크드리스트(Linked List) (0) | 2023.01.28 |
| Python 자료구조&알고리즘 - 스택(stack) (0) | 2023.01.27 |