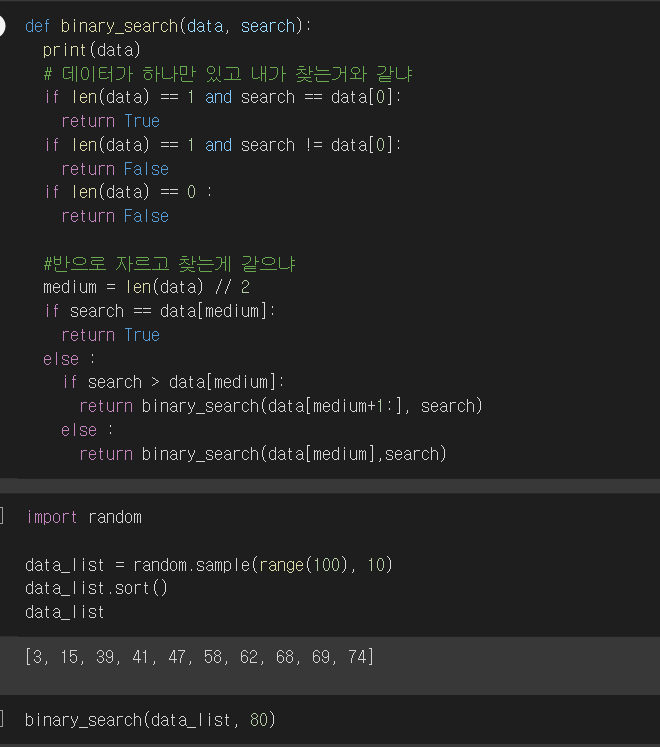
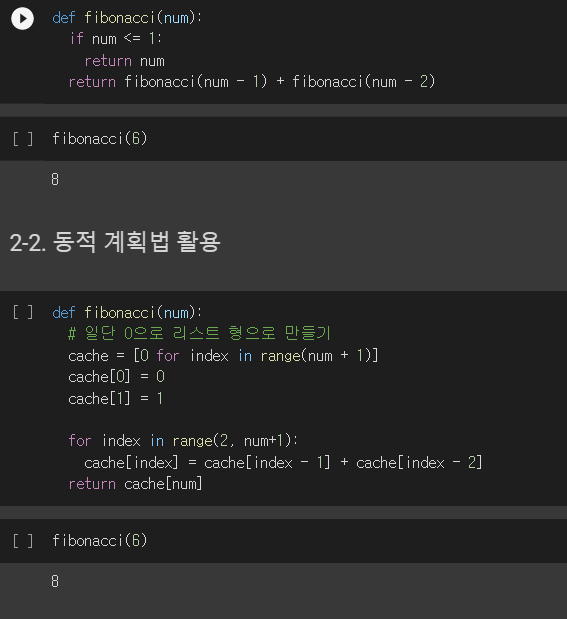
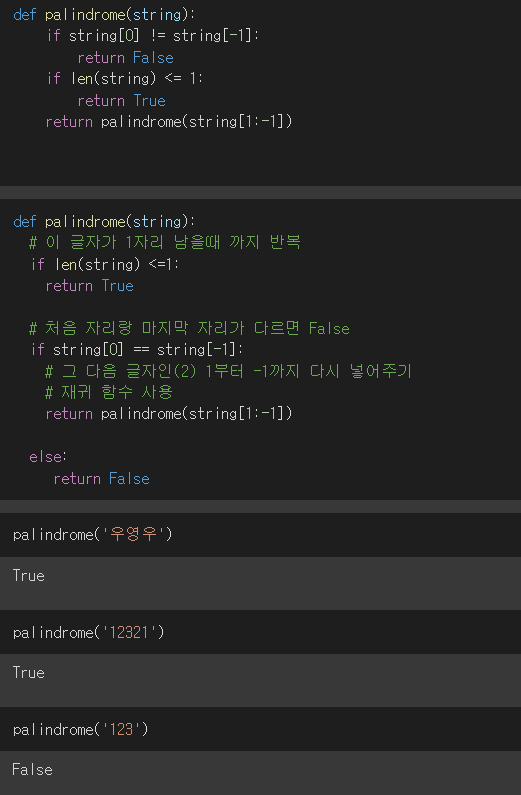
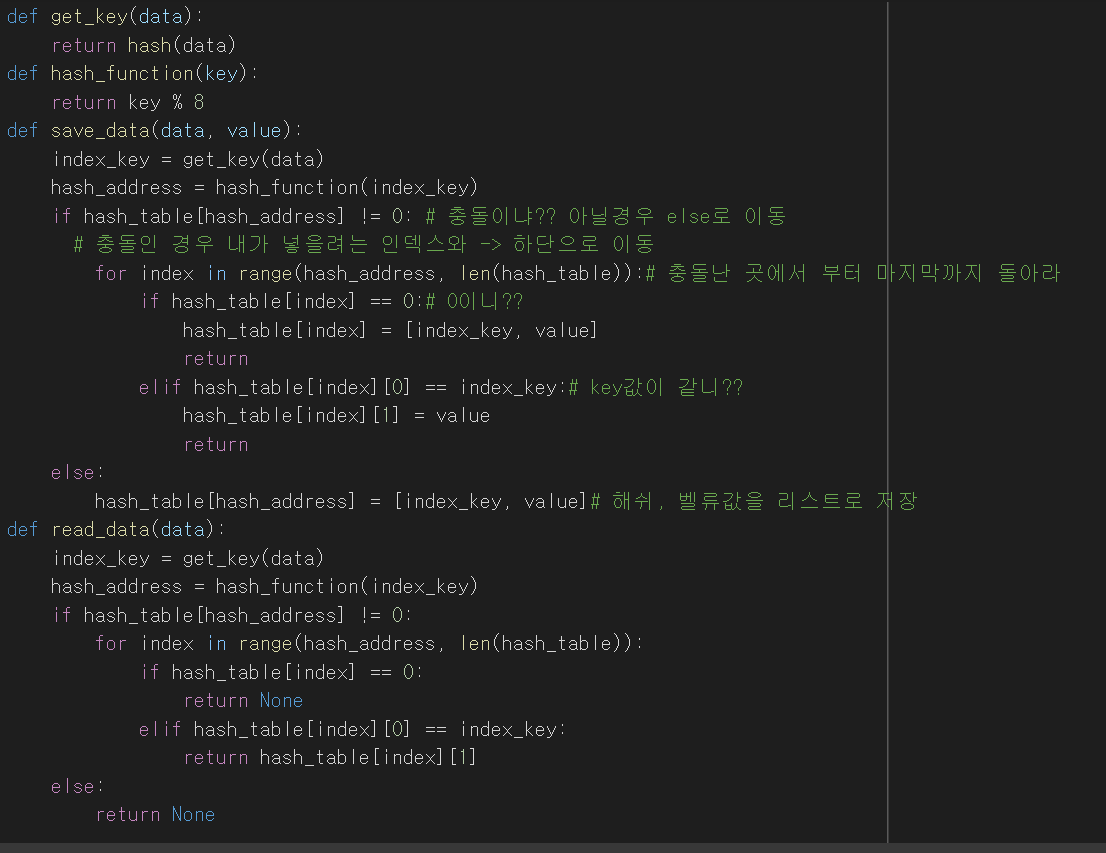
1. 그래프(Graph) 실제 세계의 현상이나 사물의 정점(Vertex) 또는 노드(Node)와 간선(Edge)으로 표현하기 위해 사 2. 그래프 관련 용어 노드(node) : 위치, 정점이라고 함 간선(edge) : 위치간의 관계를 표현한 선으로 노드를 연결한 선(link 또는 Branch라고도 함) 인접 정점(adjacent vertex) : 간선으로 직접 연결된 정점(또는 노드) 3. 그래프의 종류 3-1. 무방향 그래프 방향이 없는 그래프 간선을 통해, 노드를 양뱡향으로 갈 수 있음 3-2. 방향 그래프 간선에 방향이 있는 그래프 보통 노드 A, B가 A -> B로 가는 간선으로 연결되어 있는 경우 로 표기(와 는 다름 3-3. 가중치 그래프 간선에 비용 또는 가중치가 할당된 그래프 3-4. 연결..