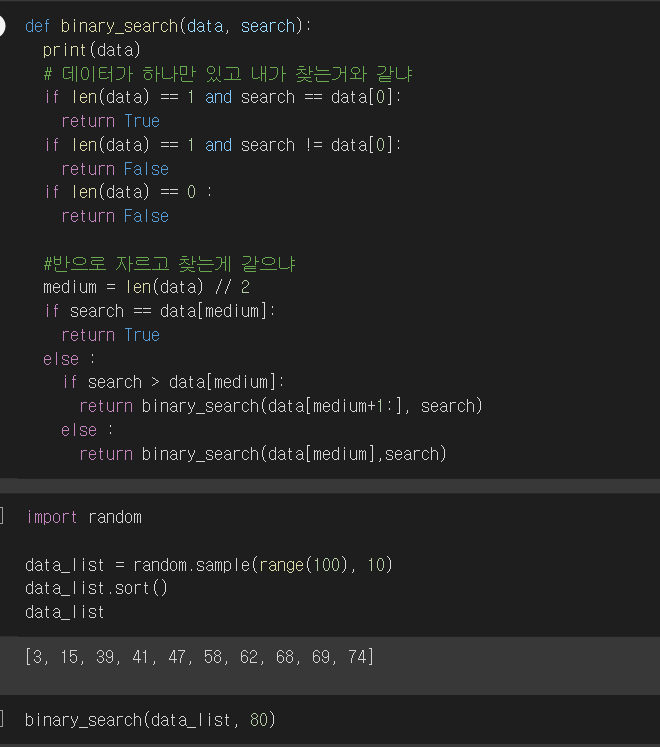
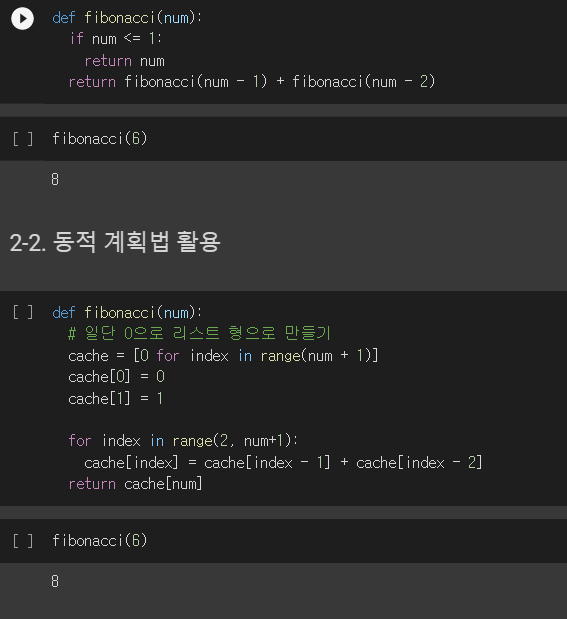
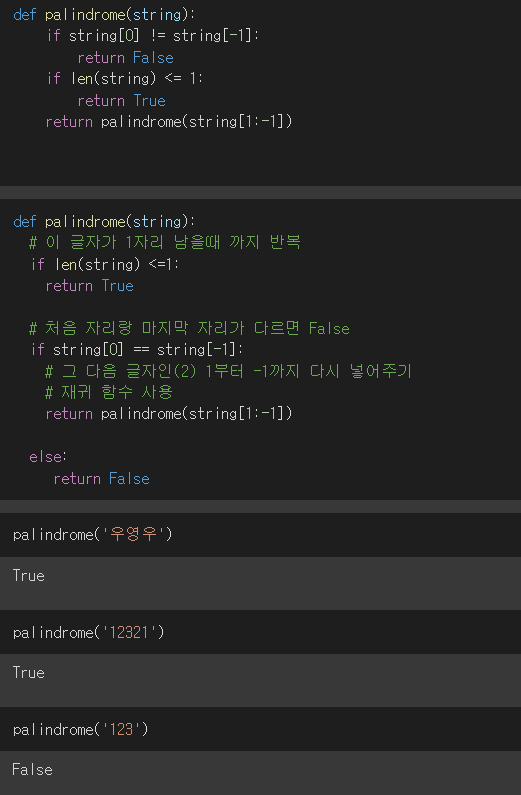
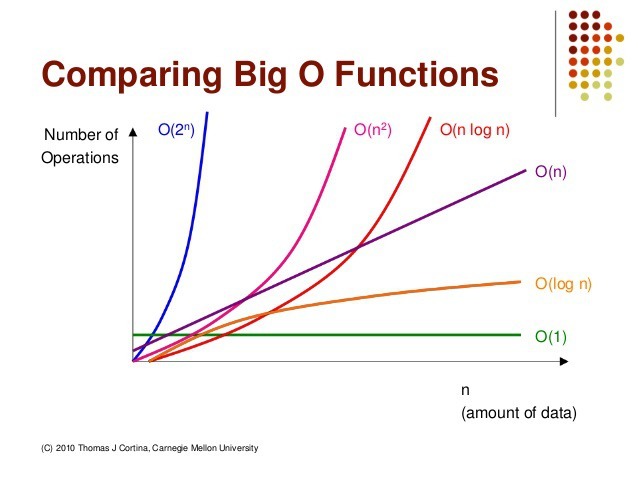
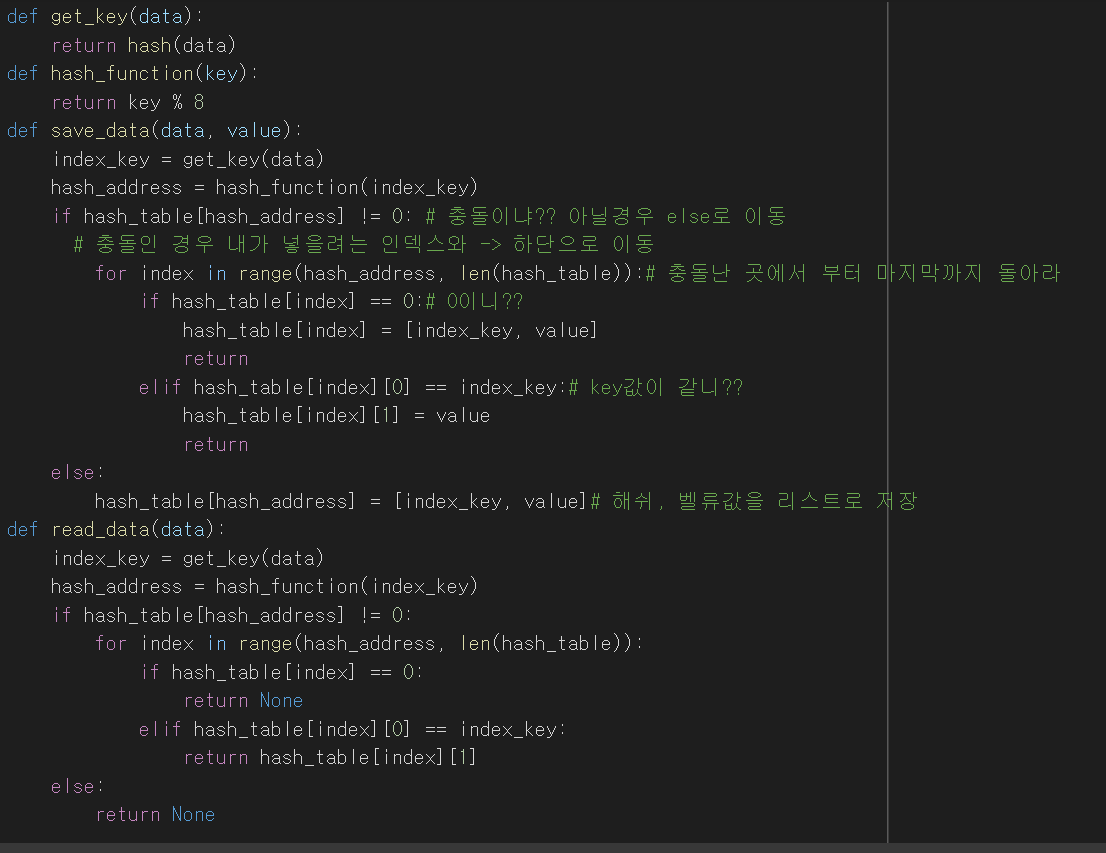
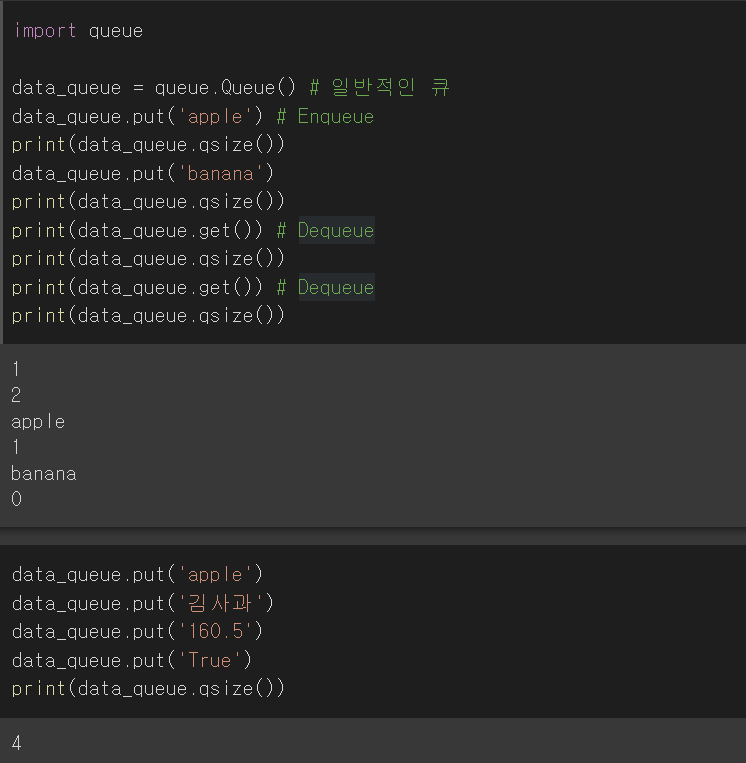
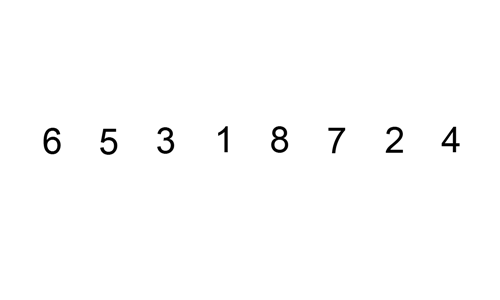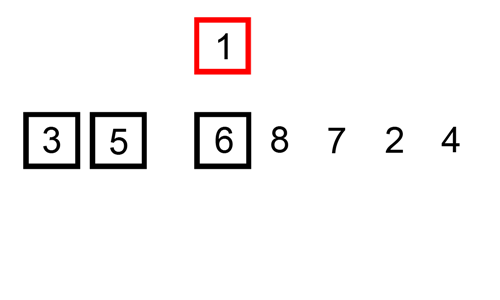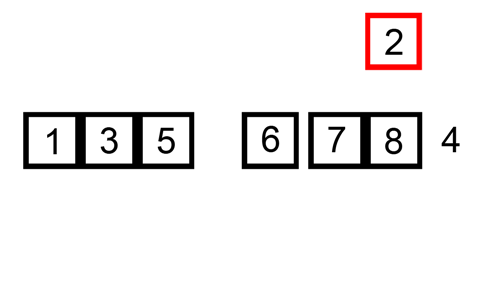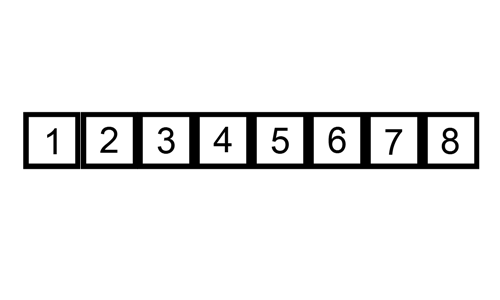1. 순차 탐색(Sequential Search) 탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미 데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법 1. 이진 탐색(Binary Search) 탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방 1-1. 이진 탐색과 순차 탐색의 비교 2. 분할 정복 알고리즘과 이진 탐색 분할 정복 알고리즘 divide : 문제를 하나 또는 둘 이상으로 나눔 conquer : 나눠진 문제가 충분히 작고 해결이 가능하면 해결하고, 그렇지 않으면 다시 나눔 이진 탐색 divide : 리스트를 두 개의 서브 리스트로 나눔 conquer : 검색할 숫자 > 증가값 : 뒷 부분의 서브 리스트에서 검색힐 숫자를 찾음 검색할 ..