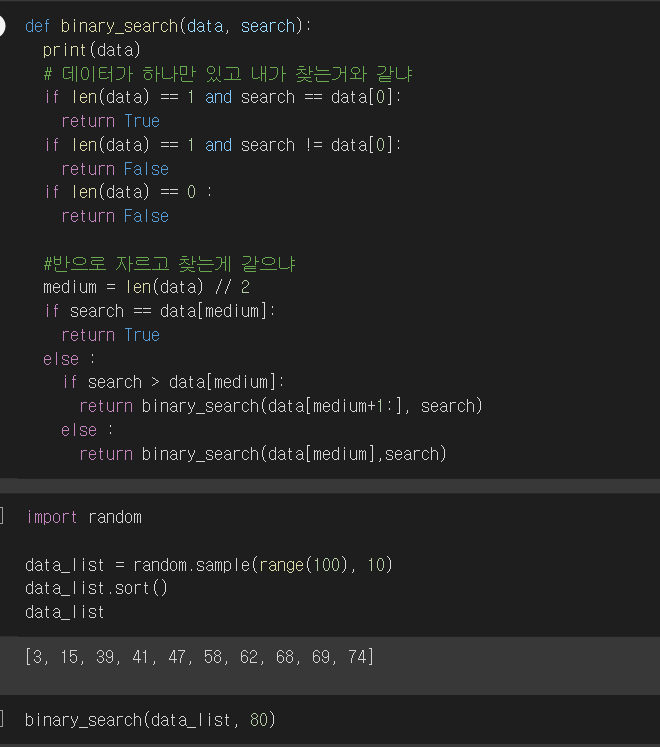
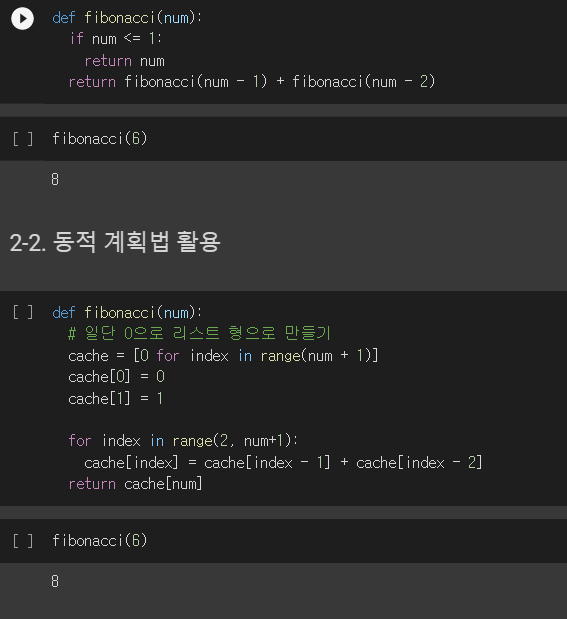
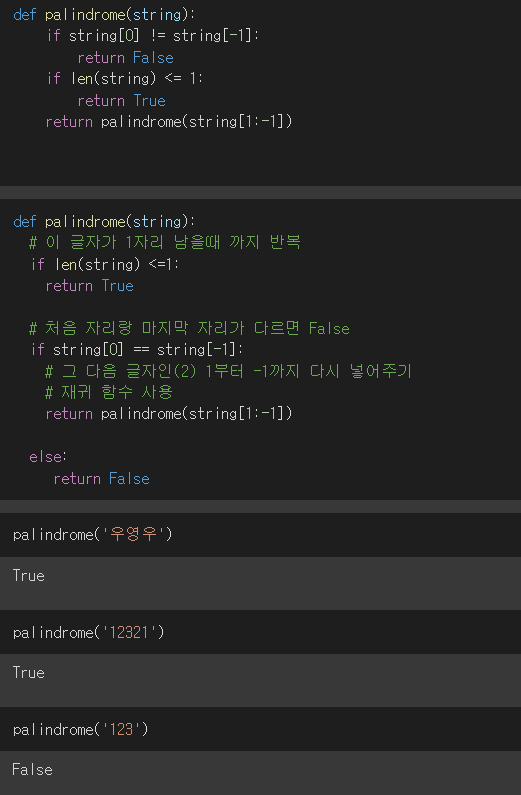
지금까지는 에측 모델이다, 로지스틱 회귀 같은 경우도 예측선을 그어주기는 하지만 데이터가 존재하는 예측선을 그어주고 서로 분류를 해주는 것이다. 예를들어 해당 범위에 있는 것을 참 거짓을 판별해준다. employee_id : 임의의 아이디 department : 부서 region : 지역 education : 학력 gender : 성별 recruitment_channel : 어떤 방식으로 채용도히었는지 no_of_trainings : 트레이닝 받은 횟수 age : 나이 previous_year_rating : 작년 고과 점수 length_of_service : 근속 년수 awards_won : 수상경력 avg_training_score : 고과 평균점수 is_promoted : 승진 여부 도큐먼트 독립변..