1. 다음은 Java 코드에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
class Main {
public static void main(String[] args) {
int[] a = new int[]{1, 2, 3, 4};
int[] b = new int[]{1, 2, 3, 4};
int[] c = new int[]{1, 2, 3};
// 첫 번째 비교: a와 b
check(a, b); // 결과: N
// 두 번째 비교: a와 c
check(a, c); // 결과: N
// 세 번째 비교: b와 c
check(b, c); // 결과: N
}
public static void check(int[] a, int[] b) {
// '==' 연산자는 참조 비교를 수행합니다.
// 두 배열의 내용이 같더라도 서로 다른 객체를 참조하면 false를 반환합니다.
if (a == b) {
System.out.print("O");
} else {
System.out.print("N");
}
}
}
답 : NNN
- 1. check(a, b):
- a와 b는 같은 내용 {1, 2, 3, 4}를 가지고 있지만, 서로 다른 배열 객체입니다.
- == 연산자는 객체의 참조를 비교하므로, 두 배열이 같은 객체를 참조하는지 확인합니다.
- a와 b는 별도로 생성된 배열이므로 서로 다른 메모리 주소를 가집니다.
- 따라서 a == b는 false가 되어 "N"이 출력됩니다.
- 2. check(a, c):
- a와 c는 내용도 다르고 (a는 4개 요소, c는 3개 요소) 서로 다른 배열 객체입니다.
- 마찬가지로 == 연산자는 참조를 비교하므로 false가 되어 "N"이 출력됩니다.
- 3. check(b, c):
- b와 c 역시 서로 다른 배열 객체입니다.
- 내용과 크기가 다르지만, == 연산자는 이를 고려하지 않고 단순히 참조만 비교합니다.
- 따라서 false가 되어 "N"이 출력됩니다.
만약 배열의 내용을 비교하고 싶다면, Arrays.equals(a, b) 메서드를 사용해야 합니다. 이 메서드는 배열의 길이와 각 요소를 비교합니다. 또는 배열의 내용을 직접 순회하면서 비교하는 로직을 구현할 수도 있습니다.
2. 다음 문제에서 설명하는 용어를 작성하시오.
데이터를 중복시켜 성능을 향상시키기 위한 기법으로 데이터를 중복 저장하거나
테이블을 합치는 등으로 성능을 향상시키지만 데이터 무결성이 저하될 수 있는 기법
답 : 반정규화
- 정규화된 데이터베이스에서 중복을 허용하거나 데이터를 모으는 과정입니다.
- 데이터의 읽기 성능을 향상시키기 위해 데이터의 중복이나 그룹화를 의도적으로 수행합니다.
3. 다음은 SQL에 관한 문제이다. 아래 SQL 구문의 빈칸을 작성하시오.
사원 [사원번호(PK), 이름, 나이, 부서]
부서 [사원번호(PK), 이름, 주소, 나이]
신입 사원이 들어와서 사원 테이블에 추가
INSERT INTO 사원 (사원번호, 이름, 주소, 부서) [ ① ] (32431, '정실기', '서울', '영업');
위에 신입사원을 검색하면서 부서 테이블에 추가
INSERT INTO 부서 (사원번호, 이름, 나이, 부서)
[ ② ] 사원번호, 이름, 나이, 23 FROM 사원 WHERE 이름 = '정실기';
전체 사원 테이블 조회
SELECT * [ ③ ] 사원;
퇴사로 인해 부서에 해당하는 값을 '퇴사'로 변경
UPDATE 사원 [ ④ ] 부서 = '퇴사' WHERE 사원번호 = 32431;
- 정답: ① VALUES 설명: INSERT INTO 문에서 새로운 레코드의 값을 지정할 때 VALUES 키워드를 사용합니다.
- 정답: ② SELECT 설명: 다른 테이블에서 데이터를 선택하여 삽입할 때 SELECT 문을 사용합니다.
- 정답: ③ FROM 설명: SELECT 문에서 데이터를 조회할 테이블을 지정할 때 FROM 키워드를 사용합니다.
- 정답: ④ SET 설명: UPDATE 문에서 변경할 열과 값을 지정할 때 SET 키워드를 사용합니다.
4. 다음 릴레이션의 Cardinality와 Degree를 작성하시오.
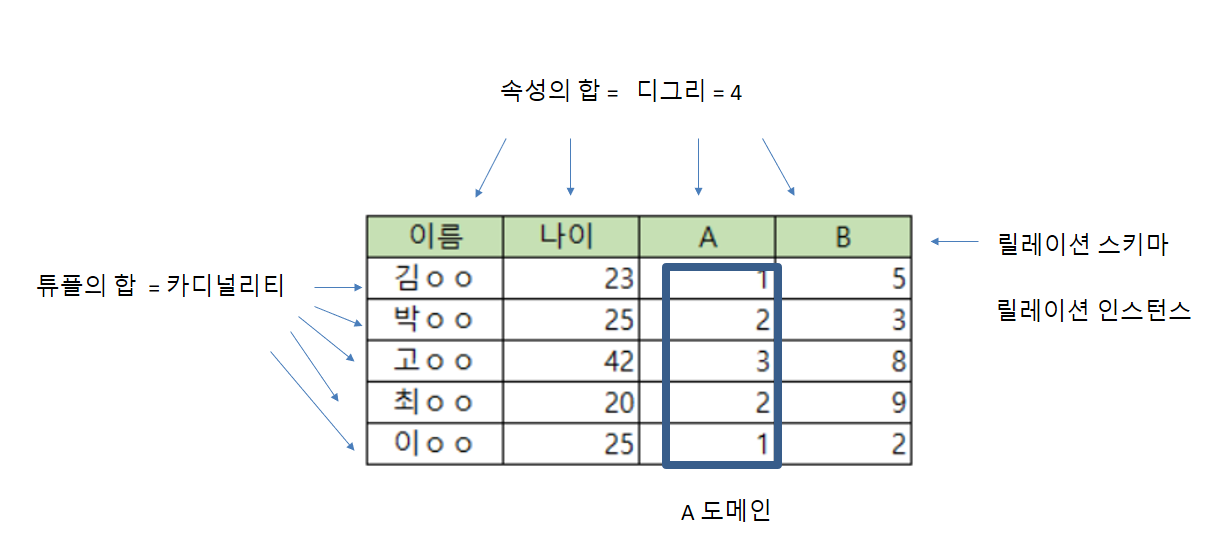
답 : Cardinality = 5 , Degree = 4
5. 다음은 프로토콜에 대한 내용이다. 아래 내용을 읽고 알맞는 답을 작성하시오.
- Network layer에서 IP패킷을 암호화하고 인증하는 등의 보안을 위한 표준이다.
- 기업에서 사설 인터넷망으로 사용할 수 있는 VPN을 구현하는데 사용되는 프로토콜이다.
- AH(Authentication Header)와 ESP(Encapsulating Security Payload)라는 두 가지 보안 프로토콜을 사용한다.
답 : IPSec
- 정의: IPsec은 Internet Protocol Security의 약자로, IP 통신에 보안을 제공하는 프로토콜 스위트입니다.
- 기능:
- IP 패킷 레벨에서 암호화와 인증을 제공합니다.
- 데이터의 기밀성, 무결성, 인증을 보장합니다.
- 사용 계층: 네트워크 계층(Network Layer)에서 동작합니다.
- 주요 용도:
- VPN(Virtual Private Network) 구현
- 안전한 원격 접속 제공
- 기업의 사설 네트워크 보안
- 주요 프로토콜:
- AH (Authentication Header): 데이터 무결성과 인증을 제공합니다.
- ESP (Encapsulating Security Payload): 암호화를 통한 기밀성과 선택적 인증을 제공합니다.
6. 다음은 Python에 대한 문제이다. 아래 코드를 읽고 알맞는 출력 값을 작성하시오.
def fnCalculation(x, y):
result = 0
for i in range(len(x)):
# x의 i번째 인덱스부터 y의 길이만큼의 부분 문자열 추출
temp = x[i:i+len(y)]
# 추출한 부분 문자열이 y와 일치하면 결과값 증가
if temp == y:
result += 1
return result
# 메인 문자열
a = "abdcabcabca"
# 검색할 부분 문자열들
p1 = "ab"
p2 = "ca"
# fnCalculation 함수를 사용하여 각 부분 문자열의 출현 횟수를 계산하고
# 결과를 특정 형식의 문자열로 조합
out = f"ab{fnCalculation(a,p1)}ca{fnCalculation(a,p2)}"
print(out) # 출력: ab3ca2
답 : ab3ca3
- fnCalculation 함수:
- 이 함수는 주어진 문자열 x 내에서 부분 문자열 y가 몇 번 나타나는지 계산합니다.
- 문자열 x를 처음부터 끝까지 순회하면서, 각 위치에서 y 길이만큼의 부분 문자열을 추출하여 y와 비교합니다.
- 일치하는 경우마다 result를 1씩 증가시킵니다.
- 메인 문자열과 검색할 부분 문자열:
- a = "abdcabcabca": 검색 대상이 되는 메인 문자열입니다.
- p1 = "ab", p2 = "ca": 검색할 두 개의 부분 문자열입니다.
- 결과 계산:
- fnCalculation(a,p1):
- "ab"가 "abdcabcabca" 내에서 3번 나타납니다 (인덱스 0, 4, 7에서 시작).
- 따라서 이 호출의 결과는 3입니다.
- fnCalculation(a,p2):
- "ca"가 "abdcabcabca" 내에서 2번 나타납니다 (인덱스 5, 9에서 시작).
- 따라서 이 호출의 결과는 2입니다.
- fnCalculation(a,p1):
- 최종 출력 문자열 생성:
- f"ab{fnCalculation(a,p1)}ca{fnCalculation(a,p2)}":
- 이 f-string은 "ab", 첫 번째 함수 호출의 결과 (3), "ca", 두 번째 함수 호출의 결과 (2)를 연결합니다.
- 따라서 최종 결과 문자열은 "ab3ca2"가 됩니다.
- f"ab{fnCalculation(a,p1)}ca{fnCalculation(a,p2)}":
7. 아래 설명하는 내용을 확인하여 알맞는 알고리즘을 작성하시오.
- 대칭키 알고리즘으로 1997년 NIST(미국 국립기술표준원)에서 DES를 대체하기 위해 생성되었다.
- 128비트, 192비트 또는 256비트의 가변 키 크기와 128비트의 고정 블록 크기를 사용한다.
- 높은 안전성과 효율성, 속도 등으로 인해 DES 대신 전 세계적으로 많이 사용되고 있다.
답 : AES
- AES는 Advanced Encryption Standard의 약자로, 고급 암호화 표준을 의미합니다.
- 개발 배경:
- 1997년 NIST(미국 국립표준기술연구소)에서 DES(Data Encryption Standard)를 대체하기 위해 공모를 시작했습니다.
- 2000년에 Rijndael 알고리즘이 AES로 선정되었습니다.
- 주요 특징:
- 대칭키 블록 암호 알고리즘입니다.
- 키 크기: 128비트, 192비트, 256비트 중 선택 가능합니다.
- 블록 크기: 고정 128비트입니다.
- 라운드 수: 키 크기에 따라 10, 12, 14라운드로 구성됩니다.
장점:
- 높은 보안성: 현재까지 실용적인 공격 방법이 알려지지 않았습니다.
- 효율성: 하드웨어와 소프트웨어에서 모두 효율적으로 구현 가능합니다.
- 속도: DES보다 빠른 암호화 및 복호화 속도를 제공합니다.
- 유연성: 다양한 키 크기를 지원하여 보안 수준을 선택할 수 있습니다.
DES는 1970년대에 IBM이 개발하고 미국 정부가 채택한 대칭키 블록 암호 알고리즘입니다.
주요 특징: 키 크기: 56비트 (실제로는 64비트이지만 8비트는 패리티 비트로 사용) 블록 크기: 64비트 16라운드의 Feistel 네트워크 구조를 사용
장단점: 장점:
구현이 간단하고 빠름 오랜 기간 사용되어 많은 분석이 이루어짐 단점: 짧은 키 길이로 인한 보안 취약성 현대의 컴퓨팅 파워로 전수 공격(brute-force attack) 가능
AES와 DES의 주요 차이점:
보안성:
AES: 128, 192, 256비트 키를 사용하여 매우 높은 보안성 제공
DES: 56비트 키로 인해 현대 컴퓨팅 환경에서 취약함
블록 크기:
AES: 128비트 고정 블록 크기
DES: 64비트
블록 크기 구조:
AES: Substitution-Permutation Network (SPN) 구조
DES: Feistel Network 구조
8. 패킷 교환 방식 중에 연결형과 비연결형에 해당하는 방식을 작성하시오.
① 연결형 교환 방식
② 비연결형 교환 방식
답 : 가상회선 , 데이터그램
① 연결형 교환 방식: 가상회선 (Virtual Circuit)
가상회선의 주요 특징:
- 정의: 데이터 전송 전에 송신자와 수신자 간에 논리적 연결을 먼저 설정하는 방식입니다.
- 작동 과정:
- 연결 설정: 데이터 전송 전 경로를 설정합니다.
- 데이터 전송: 설정된 경로를 따라 패킷들이 순서대로 전송됩니다.
- 연결 해제: 데이터 전송 완료 후 연결을 종료합니다.
- 장점:
- 패킷의 순서가 보장됩니다.
- 흐름 제어와 오류 제어가 용이합니다.
- 단점:
- 초기 연결 설정에 시간이 소요됩니다.
- 연결 유지에 추가적인 오버헤드가 발생합니다.
② 비연결형 교환 방식: 데이터그램 (Datagram)
데이터그램의 주요 특징:
- 정의: 각 패킷이 독립적으로 처리되며, 사전 연결 설정 없이 데이터를 전송하는 방식입니다.
- 작동 과정:
- 연결 설정 없음: 데이터 전송 전 별도의 경로 설정 과정이 없습니다.
- 개별 패킷 라우팅: 각 패킷은 목적지 주소를 포함하여 독립적으로 라우팅됩니다.
- 장점:
- 연결 설정 오버헤드가 없어 빠른 전송 시작이 가능합니다.
- 네트워크 자원을 효율적으로 사용할 수 있습니다.
- 단점:
- 패킷의 순서가 보장되지 않습니다.
- 패킷 손실 가능성이 있습니다.
이 두 방식은 각각 다른 상황과 요구사항에 적합하며, 네트워크 통신에서 중요한 역할을 합니다. 가상회선은 신뢰성이 중요한 경우에, 데이터그램은 빠른 전송이 필요한 경우에 주로 사용됩니다.
9. 아래 내용을 확인하고 보기에서 알맞는 답을 고르시오.
실행 순서가 밀접한 관계를 갖는 기능을 모아 모듈로 구성한다.
한 모듈 내부의 한 기능 요소에 의한 출력 자료가 다음 기능 원소의 입력 자료로서 제공되는 형태이다.
보기
ㄱ. 기능적(functional) ㄴ. 우연적(Coincidental) ㄷ. 통신적(Communication) ㄹ. 절차적(Procedural) ㅁ. 시간적(Temporal) ㅂ. 순차적(sequential) ㅅ. 논리적(Logical)
답 : 순차적
- 기능적(Functional) 응집도:
- 키워드: 단일 기능, 높은 응집도
- 설명: 모듈이 단일 잘 정의된 기능을 수행
- 순차적(Sequential) 응집도:
- 키워드: 순서, 출력-입력 연결
- 설명: 한 요소의 출력이 다음 요소의 입력으로 사용되는 순차적 실행
- 통신적(Communication) 응집도:
- 키워드: 공통 데이터, 데이터 중심
- 설명: 같은 입출력 데이터를 사용하는 요소들로 구성
- 절차적(Procedural) 응집도:
- 키워드: 프로세스, 관련 활동
- 설명: 특정 프로세스의 여러 관련 단계를 수행하는 요소들로 구성
- 시간적(Temporal) 응집도:
- 키워드: 동시 실행, 특정 시점
- 설명: 특정 시점에 함께 실행되어야 하는 기능들로 구성
- 논리적(Logical) 응집도:
- 키워드: 유사 기능, 선택적 실행
- 설명: 유사한 기능을 수행하지만 서로 관련이 없는 요소들로 구성
- 우연적(Coincidental) 응집도:
- 키워드: 무관한 기능, 낮은 응집도
- 설명: 서로 관련 없는 기능들이 우연히 같은 모듈에 묶인 경우
이 응집도 유형들은 높은 응집도(기능적)에서 낮은 응집도(우연적) 순으로 나열되어 있습니다. 일반적으로 높은 응집도를 가진 모듈 설계가 바람직합니다.
10. 아래는 디자인 패턴에 관한 설명이다. 아래 설명을 읽고 보기에서 알맞는 용어를 작성하시오.
- 컬렉션 객체의 내부 구조를 노출하지 않고 순차적으로 접근할 수 있게 하는 패턴이다.
- 이 패턴은 객체의 내부 표현 방식에 독립적으로 요소에 접근할 수 있도록 해준다
- 반복 프로세스를 캡슐화하여 클라이언트 코드에서는 컬렉션의 구체적인 구현에 종속되지 않도록 한다.
보기
| 생성패턴 | 구조패턴 | 행위패턴 |
| Singleton | Adapter | Iterator |
| Factory Method | Bridge | Visitor |
| Abstract Factory | Composite | Observer |
답 : Iterator
생성 패턴:
- Singleton:
- 키워드: 단일 인스턴스, 전역 접근점
- 설명: 클래스의 인스턴스가 하나만 생성되도록 보장
- Factory Method:
- 키워드: 객체 생성 위임, 서브클래스
- 설명: 객체 생성을 서브클래스에 위임하여 유연성 제공
- Abstract Factory:
- 키워드: 관련 객체군, 인터페이스
- 설명: 관련된 객체들의 family를 생성하기 위한 인터페이스 제공
구조 패턴:
1. Adapter:
- 키워드: 인터페이스 변환, 호환성
- 설명: 호환되지 않는 인터페이스들을 함께 동작하도록 변환
2.Bridge:
- 키워드: 구현-추상화 분리, 독립적 변화
- 설명: 추상화와 구현을 분리하여 독립적으로 변화 가능하게 함
3. Composite:
- 키워드: 트리 구조, 부분-전체 계층
- 설명: 객체들의 트리 구조를 구성하여 부분-전체 계층을 표현
행위 패턴:
1. Iterator:
- 키워드: 순차적 접근, 내부 구조 은닉
- 설명: 컬렉션의 내부 구조를 노출하지 않고 순차적 접근 제공
2. Visitor:
- 키워드: 동작 분리, 새로운 연산 추가
- 설명: 객체 구조와 동작을 분리하여 새로운 동작 쉽게 추가
3. Observer:
- 키워드: 상태 변화 통지, 일대다 의존성
- 설명: 객체 상태 변화를 다른 객체들에게 자동으로 통지
11. 아래 그림을 바탕으로 RIP을 구성하여 최단 경로 비용을 계산하여 흐름에 맞게 작성하시오.

답 : A → D → C → F
RIP (Routing Information Protocol)을 사용하여 이 네트워크의 최단 경로 비용을 계산하겠습니다. RIP는 목적지까지의 홉 수를 기반으로 최단 경로를 결정합니다
거치는 경로가 최단!!! 값이 아니라
12. 아래의 표를 확인하여 SRT 스케줄링의 평균 대기시간을 계산하여 작성하시오.
| 프로세스 | 도착 시간 | 서비스 시간 |
| A | 0 | 8 |
| B | 1 | 4 |
| C | 2 | 9 |
| D | 3 | 5 |
평균 대기시간은 (9+0+15+2)/4 = 6.5
평균 반환시간은 (17+4+24+7)/4 = 13
13. 다음은 C언어에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
#include <stdio.h>
int main() {
// 3x3 2차원 배열 초기화
int arr[3][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// 포인터 배열 초기화: arr[1]과 arr[2]의 주소를 가리킴
int* parr[2] = {arr[1], arr[2]};
// 계산 및 출력
printf("%d", parr[1][1] + *(parr[1]+2) + **parr);
return 0;
}
답 : 21
- int arr[3][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
- 3x3 2차원 배열을 초기화합니다.
- arr[0] = {1, 2, 3}
- arr[1] = {4, 5, 6}
- arr[2] = {7, 8, 9}
- int* parr[2] = {arr[1], arr[2]};
- 포인터 배열 parr을 생성하고 초기화합니다.
- parr[0]은 arr[1]의 주소를 가리킵니다 (즉, {4, 5, 6}의 시작 주소)
- parr[1]은 arr[2]의 주소를 가리킵니다 (즉, {7, 8, 9}의 시작 주소)
- printf("%d", parr[1][1] + *(parr[1]+2) + **parr); 이 부분을 세 부분으로 나누어 계산합니다:
a. parr[1][1]:
- parr[1]은 arr[2]를 가리키므로, parr[1][1]은 arr[2][1]과 같습니다.
- 따라서 parr[1][1]의 값은 8입니다.
b. *(parr[1]+2):
- parr[1]은 arr[2]의 시작 주소입니다.
- parr[1]+2는 arr[2]의 세 번째 요소를 가리킵니다.
- 따라서 *(parr[1]+2)의 값은 9입니다.
c. **parr:
- *parr은 parr[0]과 같고, 이는 arr[1]의 주소입니다.
- **parr은 arr[1]의 첫 번째 요소를 가리킵니다.
- 따라서 **parr의 값은 4입니다.
- 최종 계산: 8 + 9 + 4 = 21
14. 다음은 Java 언어에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
class Main {
public static void main(String[] args) {
// 정수 배열 초기화
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// ODDNumber 객체 생성
ODDNumber OE = new ODDNumber();
// 홀수 합과 짝수 합을 계산하여 출력
System.out.print(OE.sum(a, true) + ", " + OE.sum(a, false));
}
}
// Number 인터페이스 정의
interface Number {
int sum(int[] a, boolean odd);
}
// ODDNumber 클래스가 Number 인터페이스를 구현
class ODDNumber implements Number {
public int sum(int[] a, boolean odd) {
int result = 0;
for(int i=0; i < a.length; i++){
// odd가 true이면 홀수를, false이면 짝수를 더함
if((odd && a[i] % 2 != 0) || (!odd && a[i] % 2 == 0))
result += a[i];
}
return result;
}
}
답 : 25, 20
- int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
- 1부터 9까지의 정수를 포함하는 배열 a를 초기화합니다.
- ODDNumber OE = new ODDNumber();
- ODDNumber 클래스의 인스턴스 OE를 생성합니다.
- System.out.print(OE.sum(a, true) + ", " + OE.sum(a, false));
- OE.sum(a, true)를 호출하여 홀수의 합을 계산합니다:
- true를 전달하므로 홀수만 더합니다.
- 1 + 3 + 5 + 7 + 9 = 25
- OE.sum(a, false)를 호출하여 짝수의 합을 계산합니다:
- false를 전달하므로 짝수만 더합니다.
- 2 + 4 + 6 + 8 = 20
- OE.sum(a, true)를 호출하여 홀수의 합을 계산합니다:
- sum 메소드의 동작:
- 배열 a를 순회하면서 각 요소를 확인합니다.
- odd가 true일 때:
- a[i] % 2 != 0 조건을 만족하는 홀수만 result에 더합니다.
- odd가 false일 때:
- a[i] % 2 == 0 조건을 만족하는 짝수만 result에 더합니다.
- 최종 출력:
- 홀수의 합 25와 짝수의 합 20이 콤마로 구분되어 출력됩니다.
15. 다음은 C언어에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력값을 작성하시오.
#include <stdio.h>
#include <string.h>
// 문자열 s를 d에 복사하는 함수
void sumFn(char* d, char* s) {
int sum = 0;
while (*s) {
*d = *s; // s의 문자를 d에 복사
d++;
s++;
}
*d = '\0'; // 문자열 끝에 null 문자 추가
}
int main() {
char* str1 = "first";
char str2[50] = "teststring";
int result = 0;
sumFn(str2, str1); // str1을 str2에 복사
// str2의 각 문자 인덱스를 더함
for (int i = 0; str2[i] != '\0'; i++) {
result += i;
}
printf("%d", result);
return 0;
}
답 : 10
- char* str1 = "first";
- "first"라는 문자열을 가리키는 포인터 str1을 선언합니다.
- char str2[50] = "teststring";
- 50바이트 크기의 문자 배열 str2를 선언하고 "teststring"으로 초기화합니다.
- sumFn(str2, str1);
- sumFn 함수를 호출하여 str1의 내용을 str2에 복사합니다.
- 복사 후 str2는 "first"가 됩니다. (나머지는 null 문자로 채워집니다)
- for 루프에서의 계산:
- str2의 각 문자에 대해 그 인덱스를 result에 더합니다.
- str2는 이제 "first"이므로:
- 'f'의 인덱스: 0
- 'i'의 인덱스: 1
- 'r'의 인덱스: 2
- 's'의 인덱스: 3
- 't'의 인덱스: 4
- 따라서 result = 0 + 1 + 2 + 3 + 4 = 10
- printf("%d", result);
- 최종적으로 계산된 result 값인 10을 출력합니다.
이 코드의 주요 포인트는 다음과 같습니다:
- sumFn 함수는 실제로 문자열을 더하는 것이 아니라 복사하는 기능을 합니다.
- 원래 str2의 내용은 완전히 덮어써집니다.
- 최종 결과는 복사된 문자열 "first"의 각 문자 인덱스의 합입니다.
16. 아래는 소프트웨어 설계에 대한 내용이다. 내용을 읽고 괄호안에 알맞는 답을 작성하시오.
- 어떤 모듈이 다른 모듈 내부의 논리적인 흐름을 제어하기 위해, 제어를 통신하거나 제어 요소를 전달하는 결합도이다.
- 한 모듈이 다른 모듈의 상세한 처리 절차를 알고 있어 이를 통제하는 경우나 처리 기능이 두 모듈에 분리되어 설계된 경우에 발생한다.
( ) Coupling
답 : 제어 또는 Control
public void processData(int flag) {
if (flag == 1) {
methodA();
} else if (flag == 2) {
methodB();
}
}
이 경우, 호출하는 모듈이 flag 값을 통해 processData 메서드의 내부 동작을 제어합니다.
17. 다음은 Java에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력 값을 작성하시오.
class Main {
public static void main(String[] args) {
String str = "abacabcd";
// ASCII 문자셋(0-255)을 커버하기 위한 boolean 배열 초기화
// 각 인덱스는 ASCII 문자 코드에 대응하며, 해당 문자의 등장 여부를 표시
boolean[] seen = new boolean[256];
// 문자열의 마지막 인덱스부터 시작하여 재귀 함수 호출
System.out.print(calculFn(str, str.length()-1, seen));
}
public static String calculFn(String str, int index, boolean[] seen) {
// 기저 조건: 문자열의 시작 이전에 도달하면 빈 문자열 반환
if(index < 0) return "";
// 현재 인덱스의 문자 추출
char c = str.charAt(index);
// 재귀적으로 이전 인덱스의 결과를 먼저 얻음
// 이는 문자열을 뒤에서부터 처리하게 함
String result = calculFn(str, index-1, seen);
// 현재 문자가 아직 등장하지 않았다면
if(!seen[c]) {
// 현재 문자를 등장한 것으로 표시
seen[c] = true;
// 현재 문자를 결과 문자열의 앞에 추가
// 이는 최종 결과가 입력 문자열의 역순이 되게 함
return c + result;
}
// 이미 등장한 문자라면 결과에 추가하지 않고 그대로 반환
return result;
}
}
답 : dcba
- 입력 문자열 "abacabcd"에 대해 함수가 호출됩니다.
- 재귀 호출이 문자열의 끝에서 시작하여 앞으로 이동합니다:
- index 7 ('d'): 처음 본 문자, 결과에 추가 -> "d"
- index 6 ('c'): 처음 본 문자, 결과에 추가 -> "cd"
- index 5 ('b'): 처음 본 문자, 결과에 추가 -> "bcd"
- index 4 ('a'): 이미 본 문자, 무시 -> "bcd"
- index 3 ('c'): 이미 본 문자, 무시 -> "bcd"
- index 2 ('a'): 이미 본 문자, 무시 -> "bcd"
- index 1 ('b'): 이미 본 문자, 무시 -> "bcd"
- index 0 ('a'): 이미 본 문자, 무시 -> "bcd"
- 최종 결과는 "dcba"입니다.
18. 다음은 C언어에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력 값을 작성하시오.
#include <stdio.h>
// 이 함수는 값에 의한 전달(pass by value)을 사용하므로
// 실제로 a와 b의 값을 바꾸지 않습니다.
void swap(int a, int b) {
int t = a;
a = b;
b = t;
// 함수 종료 시 a와 b의 변경사항은 사라집니다.
}
int main() {
int a = 11;
int b = 19;
// swap 함수 호출은 실제로 a와 b의 값을 바꾸지 않습니다.
swap(a, b);
// 여기서 a는 여전히 11입니다.
switch(a) {
case 1:
b += 1; // 실행되지 않음
case 11:
b += 2; // 실행됨, b는 21이 됩니다.
default:
b += 3; // case 11 이후 break가 없어서 실행됨, b는 24가 됩니다.
break;
}
// a는 11, b는 24
printf("%d", a-b); // 11 - 24 = -13
}
답 : -13
- 변수 초기화:
- a는 11로 초기화됩니다.
- b는 19로 초기화됩니다.
- swap(a, b) 함수 호출:
- 이 함수는 값에 의한 전달(pass by value)을 사용합니다.
- 함수 내에서 a와 b의 값이 교환되지만, 이는 함수의 지역 변수에만 영향을 줍니다.
- 함수 호출이 끝나면 main 함수의 a와 b는 변경되지 않은 상태로 남습니다.
- 따라서 a는 여전히 11, b는 여전히 19입니다.
- switch 문:
- a의 값은 11이므로 case 11:부터 실행이 시작됩니다.
- case 11: 에서 b += 2가 실행되어 b는 21이 됩니다.
- case 11: 다음에 break가 없으므로 실행이 계속되어 default: 케이스로 넘어갑니다.
- default: 에서 b += 3이 실행되어 b는 24가 됩니다.
- break를 만나 switch 문이 종료됩니다.
- 최종 계산 및 출력:
- a는 11로 유지되고 있습니다.
- b는 24가 되었습니다.
- a - b는 11 - 24 = -13 입니다.
- 따라서 -13이 출력됩니다.
swap 함수에 포인터를 주었으면 값이 바뀌었지만 사용을 안했으므로 지역변수에서만 사용이 되고 실제로 변경이 되지 않는다.
19. 다음은 C언어의 구조체에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력 값을 작성하시오.
#include <stdio.h>
// 노드 구조체 정의
struct node {
int n1; // 정수 데이터를 저장하는 멤버
struct node *n2; // 다음 노드를 가리키는 포인터
};
int main() {
// 세 개의 노드 생성 및 초기화
struct node a = {10, NULL};
struct node b = {20, NULL};
struct node c = {30, NULL};
// 연결 리스트의 시작점(head) 설정
struct node *head = &a;
// 노드들을 연결
a.n2 = &b;
b.n2 = &c;
// head->n2->n1 출력 (즉, b 노드의 n1 값)
printf("%d\n", head->n2->n1);
return 0;
}
답 : 20
- 구조체 정의:
- node 구조체는 정수 n1과 다음 노드를 가리키는 포인터 n2로 구성됩니다.
- 노드 생성 및 초기화:
- a, b, c 세 개의 node 구조체 변수를 생성합니다.
- 각각 10, 20, 30의 값으로 n1을 초기화하고, n2는 NULL로 초기화합니다.
- 연결 리스트 구성:
- head 포인터를 a 노드의 주소로 초기화합니다. 이는 리스트의 시작점이 됩니다.
- a.n2 = &b;로 a 노드의 n2가 b 노드를 가리키게 합니다.
- b.n2 = &c;로 b 노드의 n2가 c 노드를 가리키게 합니다.
- 데이터 접근 및 출력:
- head->n2->n1을 출력합니다. 이는 다음과 같이 해석됩니다:
- head는 a 노드를 가리킵니다.
- head->n2는 a 노드의 n2, 즉 b 노드를 가리킵니다.
- head->n2->n1은 b 노드의 n1 값, 즉 20을 의미합니다.
- head->n2->n1을 출력합니다. 이는 다음과 같이 해석됩니다:
따라서, 이 코드의 출력 결과는 20입니다.
이 코드는 간단한 연결 리스트의 구조를 보여줍니다:
- a → b → c → NULL
각 노드는 데이터(n1)와 다음 노드를 가리키는 포인터(n2)를 가지고 있으며, 이를 통해 노드들이 서로 연결되어 있습니다. 이러한 구조는 데이터의 동적인 추가와 삭제가 용이한 연결 리스트의 기본 개념을 잘 나타내고 있습니다.
20. 다음은 Java에 대한 문제이다. 아래 코드를 확인하여 알맞는 출력 값을 작성하시오.
class Main {
public static void main(String[] args) {
String str = "ITISTESTSTRING";
// "T"를 구분자로 문자열을 분할
String[] result = str.split("T");
// 분할된 결과의 네 번째 요소(인덕스 3) 출력
System.out.print(result[3]);
}
}
답 : S
- 문자열 초기화:
- str 변수에 "ITISTESTSTRING" 문자열이 할당됩니다.
- 문자열 분할:
- str.split("T")는 "T"를 구분자로 사용하여 문자열을 분할합니다.
- 이 분할 결과는 다음과 같습니다: result[0] = "I" result[1] = "IS" result[2] = "ES" result[3] = "S" result[4] = "RING"
- 결과 출력:
- System.out.print(result[3]);는 분할된 결과의 네 번째 요소(인덱스 3)를 출력합니다.
- 이는 "S"입니다.
'Lisence > 정보처리기사' 카테고리의 다른 글
| [2024 정처기 실기 3회] 정보처리기사 3회 실기 해설 및 설명 (1) | 2025.04.19 |
|---|---|
| 정보처리기사 실기 코딩 알고리즘 Python 최신 문제 정리 해설 - 24년 대비 (1) | 2024.04.20 |
| 정보처리기사 실기 코딩 알고리즘 C언어 최신 문제 정리 해설 - 24년 대비 (4) | 2024.04.19 |
| 정보처리기사 실기 기본 알고리즘 공부 2 (0) | 2023.04.12 |
| 정보처리기사 실기 기본 알고리즘 공부 (0) | 2023.04.11 |