11. 모델 검증을 위한 Accuracy 생성하기
@torch.no_grad() # 아래 붙어 있는함수가 작동을 할때
def get_accuracy(image, target, model):
batch_size = image.shape[0]
prediction = model(image)
_, pred_label = torch.max(prediction, dim=1)
is_correct = (pred_label == target)
return is_correct.cpu().numpy().sum() / batch_size12. 모델 학습을 위한 함수 구현하기
# 모델을 학습하기 위한 함수를 만들어보자
device = torch.device('cpu')
# epcoh: 데이터 전체를 한바퀴를 돌리는것?
# model: 우리가 학습한 모델
def train_one_epoch(dataloaders, model, optimizer, loss_func, device):
losses = {} # 딕셔너리 타입으로 만들어준다...
accuracies = {}
for tv in ['train', 'val']:
running_loss = 0.0 # 얼마만큼 틀렸니를 누적...
running_correct = 0 # 얼마만큼 맞았니를 누적...
if tv == 'train':
model.train() # 학습을 시킨다...
else:
model.eval() # 학습에 대한 메모리는 날리고 검증에 대한 메모리만 남긴다... no_grad()와 비슷...
for index, batch in enumerate(dataloaders[tv]): # dataloaders 라는 객체에 train or val를 넣어준다...
image = batch['image'].to(device)
target = batch['target'].squeeze(dim=1).to(device) # squeeze: 차원축소, dim=1로 하면 1차원으롤 줄여주고, 값이 없으면 한차원 줄여줌
# with : 파일 입출력에서 open을 사용하면 이 메소드들에 의해 사용되는 경우가 많은데, 마지막에 파일같은 경우에는
# close를 해줘야 하는데 with를 하면 open하고 closs 할 필요가 없고 with내에 들여쓰기하여 사용을 하면 된다.
# set_grad_enabled : 함수의미는 역전파 시키는 객체들을 메모리에 올려준다(학습에 필요한 데이터)
# with문은 if문이 아니고 train일 때 이 함수를 사용하라는 거지 다른 경우도 들어올 수 있다.
with torch.set_grad_enabled(tv == 'train'): # with: with문 밖으로 나가면 자원이 반납된다... val이어도 안으로 들어간다...
prediction = model(image) # 모델에 이미지를 넣어서 예측값을 구한다...
loss = loss_func(prediction, target)
if tv == 'train':
optimizer.zero_grad() # zero_grad(): 기울기 초기화 시키라는...안해주면 틀린 loss값을 누적하게 된다.
# 옵티마이저 : SGD를 사용, zero_grad() : 초기화 시켜아
# 이 옵티마이저는 실제 예측값을 구하고 차를 구해
# 직선의 방정식에 의한 예측값을 뽑아 후에
# 미분을 구해 어느 쪽으로 이동해야 하는지 학습률만큼 이동을 하고 기울기가 같은 것으로
# 초기화를 안하면 기울기 값을 구해야 하는데 계속 값이 추가되어
loss.backward() # 역전파 계산, 미분
optimizer.step() # 새로운 기울기 적용
running_loss += loss.item()
running_correct += get_accuracy(image, target, model)
if tv == 'train':
if index % 10 == 0:
print(f"{index}/{len(dataloaders['train'])} - Running loss: {loss.item()}")
losses[tv] = running_loss / len(dataloaders[tv])
accuracies[tv] = running_correct / len(dataloaders[tv])
return losses, accuracies
# 예측할때마다 학습을 시킨다면 오래걸리니 학습시킨 파일로 만들어준다
# 모델을 저장한 파일을 생기게 만든다. 학습하면서 저장위해 계속 학습보단 있는 내용을 파일로 저장해서 활용하자
def save_best_model(model_state, model_name, save_dir='./trained_model'):
os.makedirs(save_dir, exist_ok=True) # 존재하면 덮어쓰겠다...
torch.save(model_state, os.path.join(save_dir, model_name)) # 좋을때마다 저장해준다...
# 계속 저장을 하면 너무 쓰잘데 없는 파일이 많이 생기기 때문에 로스 값이 적을 때만 저장을 할 조건을 정의하자13. 모델 학습 수행하기
device = torch.device('cpu')
train_data_dir = './Covid19-dataset/train'
val_data_dir = './Covid19-dataset/test'
dataloaders = build_dataloader(train_data_dir, val_data_dir)
model = build_vgg19_based_model(device_name='cpu')
loss_func = nn.CrossEntropyLoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=1E-3, momentum=0.9)
# num_epochs = 10 : 학습할 epoch 수를 설정합니다. 즉, 데이터셋 전체를 10번 반복하여 학습합니다.
# best_acc = 0.0 : 현재까지 최고 정확도를 저장하는 변수를 0.0으로 초기화합니다.
# train_loss, train_accuracy = [], [] : 학습 데이터셋의 손실과 정확도를 저장하기 위한 리스트를 생성합니다.
# val_loss, val_accuracy = [], [] : 검증 데이터셋의 손실과 정확도를 저장하기 위한 리스트를 생성합니다.
# 그리고 for loop을 통해 epoch 수만큼 반복하면서 다음 작업을 수행합니다.
# train_one_epoch 함수를 호출하여 학습을 수행합니다. 이 함수는 dataloaders에서 가져온 배치 데이터를 사용하여 모델을 학습하고, 학습 데이터셋과 검증 데이터셋의 손실과 정확도를 계산합니다.
# 각 epoch 마다 학습 데이터셋과 검증 데이터셋의 손실과 정확도를 각각의 리스트에 추가합니다.
# 학습 정보를 출력합니다.
# 만약 epoch 수가 3보다 크고 검증 데이터셋의 정확도가 현재까지의 최고 정확도보다 높은 경우, 모델의 상태를 best_model에 저장하고 최고 정확도를 best_acc에 저장합니다. 그리고 save_best_model 함수를 호출하여 최고 모델을 파일로 저장합니다.
# 최종적으로 최고 정확도를 출력합니다.
# 위 코드는 학습 과정에서 모델의 성능을 모니터링하고, 최고 성능을 달성한 모델의 상태를 저장하는 등의 다양한 기능을 포함하고 있습니다.
num_epochs = 10
best_acc = 0.0 # 가장 좋은 에크러시를 저장한다.
train_loss, train_accuracy = [], []
val_loss, val_accuracy = [], []
for epoch in range(num_epochs):
losses, accuracies = train_one_epoch(dataloaders, model, optimizer, loss_func, device)
train_loss.append(losses['train'])
val_loss.append(losses['val'])
train_accuracy.append(accuracies['train'])
val_accuracy.append(accuracies['val'])
print(f"{epoch+1}/{num_epochs} - Train Loss:{losses['train']}, val_Loss:{losses['val']}")
print(f"{epoch+1}/{num_epochs} - Train Loss:{accuracies['train']}, val_Loss:{accuracies['val']}")
if(epoch > 3) and (accuracies['val'] > best_acc):
best_acc = accuracies['val']
best_model = copy.deepcopy(model.state_dict())
save_best_model(best_model, f'model_{epoch+1:02d}.pth')
print(f'Best Accracy: {best_acc}')# num_epochs = 10 : 학습할 epoch 수를 설정합니다. 즉, 데이터셋 전체를 10번 반복하여 학습합니다.
# best_acc = 0.0 : 현재까지 최고 정확도를 저장하는 변수를 0.0으로 초기화합니다.
# train_loss, train_accuracy = [], [] : 학습 데이터셋의 손실과 정확도를 저장하기 위한 리스트를 생성합니다.
# val_loss, val_accuracy = [], [] : 검증 데이터셋의 손실과 정확도를 저장하기 위한 리스트를 생성합니다.
# 그리고 for loop을 통해 epoch 수만큼 반복하면서 다음 작업을 수행합니다.
# train_one_epoch 함수를 호출하여 학습을 수행합니다. 이 함수는 dataloaders에서 가져온 배치 데이터를 사용하여 모델을 학습하고, 학습 데이터셋과 검증 데이터셋의 손실과 정확도를 계산합니다.
# 각 epoch 마다 학습 데이터셋과 검증 데이터셋의 손실과 정확도를 각각의 리스트에 추가합니다.
# 학습 정보를 출력합니다.
# 만약 epoch 수가 3보다 크고 검증 데이터셋의 정확도가 현재까지의 최고 정확도보다 높은 경우, 모델의 상태를 best_model에 저장하고 최고 정확도를 best_acc에 저장합니다. 그리고 save_best_model 함수를 호출하여 최고 모델을 파일로 저장합니다.
# 최종적으로 최고 정확도를 출력합니다.
# 위 코드는 학습 과정에서 모델의 성능을 모니터링하고, 최고 성능을 달성한 모델의 상태를 저장하는 등의 다양한 기능을 포함하고 있습니다.
plt.figure(figsize=(6, 5))
plt.subplot(211)
plt.plot(train_loss, label='train')
plt.plot(val_loss, label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid('on')
plt.legend()
plt.subplot(212)
plt.plot(train_accuracy, label='train')
plt.plot(val_accuracy, label='val')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid('on')
plt.legend()
plt.tight_layout()
14. 테스트 이미지를 통한 학습모델 분류 성능 검증하기
data_dir = './Covid19-dataset/test/'
class_list = ['Normal', 'Covid', 'Viral Pneumonia']
test_normals_list = list_image_file(data_dir, 'Normal')
test_covids_list = list_image_file(data_dir, 'Covid')
test_pneumonias_list = list_image_file(data_dir, 'Viral Pneumonia')def preprocess_image(image):
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]) # 값을 범위안에 들어가도록 재조정하는 것... 스탠다드스케일업
])
tensor_image = transformer(image) # C, H, W
tensor_image = tensor_image.unsqueeze(0) # 차원증가 B(batch), C, H, W
return tensor_imagedef model_predict(image, model):
tensor_image = preprocess_image(image) # 전처리
prediction = model(tensor_image) # 예측
_, pred_label = torch.max(prediction.detach(), dim=1) # 라벨을 떼서 최고값을 구함
print('prediction.detach: ', prediction.detach())
print('pred_label: ', pred_label)
pred_label = pred_label.squeeze(0)
print('pred_label2: ', pred_label)
return pred_label.item()
ckpt = torch.load('./trained_model/model_07.pth')
model = build_vgg19_based_model()
model.load_state_dict(ckpt) # 학습된 모델을 넣어줌
model.eval()min_num_files = min(len(normals_list), len(covids_list), len(pneumonias_list))
@interact(index=(0, min_num_files-1))
def show_result(index=0):
normal_image = get_RGB_image(data_dir, test_normals_list[index])
covid_image = get_RGB_image(data_dir, test_covids_list[index])
pneumonia_image = get_RGB_image(data_dir, test_pneumonias_list[index])
prediction_1 = model_predict(normal_image, model)
prediction_2 = model_predict(covid_image, model)
prediction_3 = model_predict(pneumonia_image, model)
plt.figure(figsize=(12, 8))
plt.subplot(131)
plt.title(f'Pred:{class_list[prediction_1]} | GT:Normal')
plt.imshow(normal_image)
plt.subplot(132)
plt.title(f'Pred:{class_list[prediction_2]} | GT:Covid')
plt.imshow(covid_image)
plt.subplot(133)
plt.title(f'Pred:{class_list[prediction_3]} | GT:Pneumonia')
plt.imshow(pneumonia_image)
plt.tight_layout()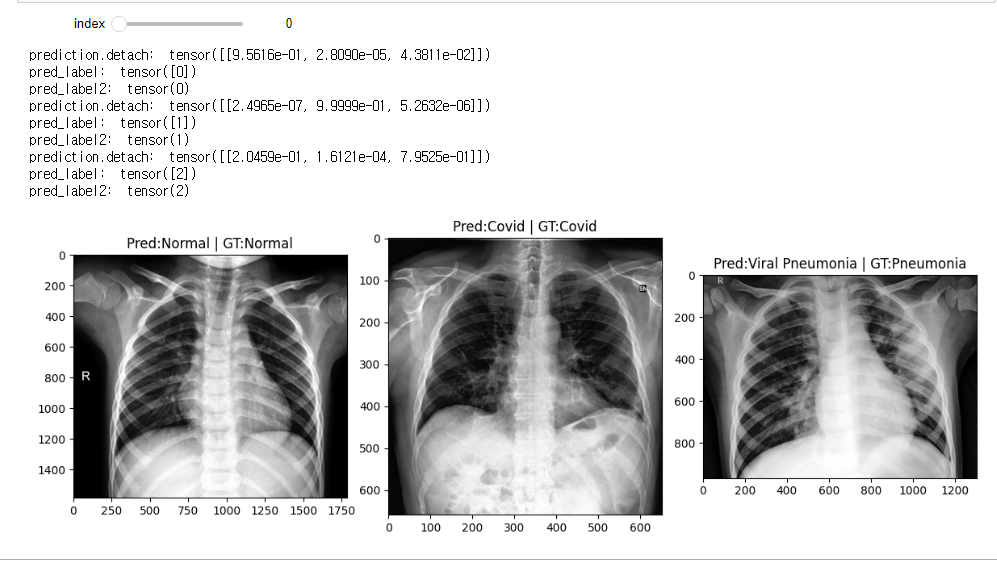
15. 결론
- CNN에 대한 학습
- 이미지 데이터셋 구축
- Torchvision transforms 라이브러리를 활용한 텐서형 데이터 변환
- VGG 19 모델을 불러와 Head 부분을 수정
- Cross entropy Loss Function, SGDM 적용
- 인간 추론원리와 닮은 딥러닝 결과 출력
'대학원 시험 공부' 카테고리의 다른 글
| 운동자세 인식 프로젝트 사전 준비 및 공부 (1) | 2023.04.09 |
|---|---|
| 데이터분석 프로젝트 (파이썬 Covid-19 사진 학습(분류) 2) (1) | 2023.03.27 |
| 데이터분석 프로젝트(파이썬 Covid-19 사진 학습(분류) 1) (1) | 2023.03.25 |
| 파이토치 (0) | 2023.02.28 |
| 텐서플로우 (1) | 2023.02.27 |